지난 일지 #1 에서는 가장 단순한 에이전트를 구현했다. 이번엔 State 에 메시지 외 다양한 정보를 추가 하고 시스템 프롬프트를 활용 해서 좀 더 응용해본다.
Table of contents
Open Table of contents
1. 라우팅 함수 다시 보기
저번 구현에서 주의 깊게 안 봤던 라우팅 함수 를 다시 봤다.
add_conditional_edges로 분기를 만든다- 라우팅 함수가 반환하는 문자열 과 일치하는 이름의 노드 로 흐름을 보냄
- 그 매핑은
add_conditional_edges인자로 dict 형태로 줌
2. State 에 메시지 외 정보 추가
AgentState 에서 메시지만 관리하는 게 아니라 다른 것들도 같이 관리:
- 유저 이름
- tool 호출 횟수
- 세션 시작 시간
- 기타 컨텍스트 정보
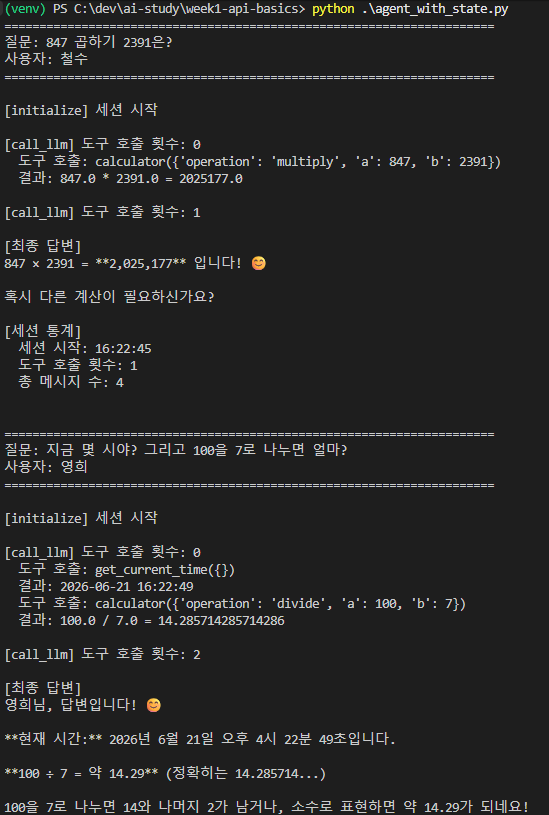
결과를 보면 메시지를 어떤 걸 받았는지뿐 아니라:
- 현재 사용자가 누군지
- 도구 호출은 얼마나 했는지
- 세션 시작은 언제 됐는지
같이 State 에서 확인 가능. 미리 준비한 State 의 정보를 답변에도 활용했다.
3. State 정보로 시스템 프롬프트 동적 구성
시스템 프롬프트에 State 정보를 끼워넣어서 답변하게 했더니, 규칙에 입각한 답변 이 잘 나왔다. 이걸 State 를 이용해 시스템 프롬프트를 동적으로 구성한다 고 한다.
이 패턴이 있어야 같은 그래프로 사용자마다 다른 컨텍스트 의 응답이 가능해진다. 사용자 A 에겐 “박효인님, 도구 3번 사용하셨네요” / 사용자 B 에겐 “민수님, 처음이시군요” 같이.
학습 노트용 LangGraph 로 응용
이걸 응용해서 학습 노트 관련 LangGraph 를 만들었다. State 에:
- 학습 연속 일수
- 현재 사용자가 어느 단계까지 공부했는지
같은 정보를 관리하고, 그걸 시스템 프롬프트에 넣었다. 결과:
일반적인 LLM 이라면 답변 못했을 내용 도 적절하게 잘 답변했다.
지금 내가 실행한 환경은 하나의 케이스이지만, 여러 사용자가 이용할 때에도 각자의 State 가 입력될 것이기 때문에 현재 구조 그대로 사용 가능 할 것이다.
4. 챗봇 구현 — 대화 이어지기
이전엔 함수 호출 한 번에 답변 을 보는 형태였다. 이번엔 대화가 이어지도록 챗봇으로 구현.
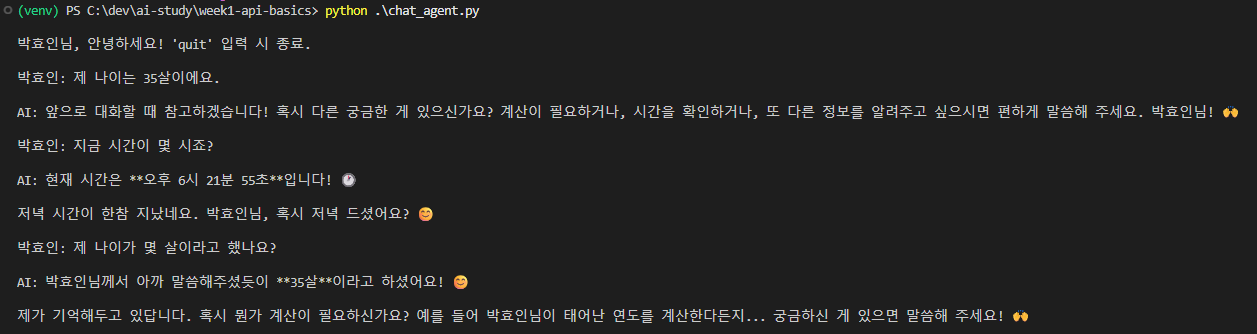
신기한 게 — 함수로 구현한 tool 중에 “그냥 기억하라” 라는 말만 적혀있는데, 내 나이를 기억할 수 있는 게 이상했다. “어떻게 알았지?” 가 첫 반응.
5. “AI 가 기억한다” 의 정체 — Tool 이 아니라 메시지 누적
알고 보니 위의 tool 이 실제로 동작한 게 아니었다. 그냥 지난 메시지 목록에 내가 얘기했던 게 저장되어 있어서 기억하는 거 였다. LLM 이 매 호출마다 전체 대화 히스토리를 컨텍스트로 받기 때문에, 별도 메모리 없이도 “기억하는 것처럼” 보인다.
그러면 진짜 메모리는?
진짜 persistent memory 를 만들려면:
- JSON 파일에 저장 (간단한 영속화)
- State 에 별도 저장 공간 추가 (그래프 안에서 누적)
- 벡터 DB 에 저장 (의미 기반 검색 가능, RAG 글 패턴)
대화 히스토리는 컨텍스트 윈도우 한계가 있으니, 긴 대화에선 위 방식 중 하나가 결국 필요해진다.
이 깨달음이 오늘 핵심. “AI 가 기억한다” 는 표현은 실제론 두 가지가 섞여있다 — 단기 (메시지 누적) vs 장기 (외부 저장).
회고 — 설계 능력의 중요성
구현해보니까 역시나 설계가 정말 중요 하다는 것을 다시 느꼈다. 이렇게 좋은 툴이 있는데:
- 내가 이걸 어디에 쓸 거고
- 현재 상황에서 쓸 수 있는지 없는지 판단하고
- 어떻게 쓸지 정해야
구현을 시작조차 할 수 있다. 어떤 기능이 필요한지, 어떤 pain 을 해결할지에 대해 민감하게 알아차릴 수 있는 실력 이 필요하다.
LangGraph 같은 도구의 강점은 모듈성 (State + 노드 + 엣지 + 분기) 인데, 그걸 어떤 시나리오에 어떻게 매핑할지 가 결국 사람 (또는 페어 프로그래밍하는 AI) 의 몫이다.
다음 할 것
- 진짜 persistent memory 구현 (JSON / State 누적 / 벡터 DB 중 하나로)
- 멀티 유저 환경 시뮬레이션 — 세션별 State 분리
- LangGraph 의
add_messagesreducer 와MessagesState다뤄보기
더 공부해볼 것
1. LangChain / LangGraph 의 Memory 모듈
ConversationBufferMemory(전체 히스토리) vsConversationSummaryMemory(요약본 누적)VectorStoreRetrieverMemory— 벡터 DB 기반 의미 기반 회상- LangGraph 자체의 checkpointer 와 thread-level 영속화
- 단기 (컨텍스트 윈도우) vs 장기 (외부 저장) 의 경계 설계
2. State 영속화 — Postgres / Redis / Checkpointer
- LangGraph 의
MemorySaver,PostgresSaver,RedisSaver - 서버 재시작 후에도 대화가 이어지는 구조
- 멀티 사용자에서 thread_id 로 세션 분리하는 패턴
3. 시스템 프롬프트의 동적 구성 패턴
- State → 시스템 프롬프트 (이번에 만짐)
-
- Few-shot examples 도 State 에서 동적으로 골라 넣기
-
- Tool 선택 도 State 기반으로 (사용자 역할에 따라 admin tool 노출 여부)
4. MessagesState + add_messages reducer
- 다음 일지에서 다뤄볼 예정
- 노드 여러 개가 동시에 메시지를 추가할 때 충돌 없이 누적하는 방법
- 기본 dict 와의 차이
5. “Memory” 의 용어 정리 — 너무 많아서 헷갈림
- Short-term memory (= context window)
- Long-term memory (= 외부 저장)
- Episodic memory (특정 사건 회상) vs Semantic memory (사실 누적)
- Working memory (현재 작업 중인 정보)
- AI 분야에서 이 용어들이 인지과학에서 가져온 것인데 LangGraph 문서에서 자주 섞임