어제 RAG 의 부품들 (임베딩 / 코사인 유사도 / 청크) 을 만져봤다. 오늘은 그 부품을 시스템으로 통합. 순서:
- 벡터 DB (Chroma) 도입
- 내 학습 노트 (블로그 글) 를 코퍼스로
- 청크 분할 + 인덱스 빌드
- LLM 결합한 Q&A 시스템
말로만 보면 잘 안 와닿는다. 구현해보면서 감 잡았다.
Table of contents
Open Table of contents
1. Chroma 도입 — numpy 대신 벡터 DB
어제는 numpy 로 직접 임베딩·검색했다. 실전에서는 벡터 DB 를 쓴다. 이유:
- 검색 속도 — 인덱스 알고리즘 (HNSW 등) 으로 ANN 검색
- 영속성 — 한 번 임베딩한 걸 디스크에 저장
- 메타데이터 관리 — 청크에 출처 / 작성일 / 태그 등 함께 보관
Chroma 가 가장 진입 쉬운 오픈소스 옵션. pip install chromadb 한 줄로 끝.

어제 봤던 코사인 유사도와는 값이 다르다는 게 눈에 띈다. Chroma 기본은 L2 distance — 0에 가까울수록 유사, 2에 가까울수록 다름 (코사인은 1이 유사, -1이 반대).
결과를 보면:
- 첫 질문 답이 잘못됨 + 1·2위 점수 차이도 작음 → 검색 품질 의심 신호
- 제대로 답한 경우는 1·2위 점수 차이가 분명함
PersistentClient 라서 한 번 임베딩한 건 다시 안 만들어도 됨. 재실행이 짧게 끝나는 게 그래서.
2. 블로그 글을 코퍼스로 — glob

따로 학습 기록을 저장한 게 없다. 블로그 글을 데이터로 쓰면 되겠다 싶었다. glob.glob 한 줄로 .md 파일 전체 로드.
3. 청크 분할 — re 에서 frontmatter 로
다음 단계는 노트를 청크로 분할.
처음엔 잘 됐다 싶었는데 코드를 보니까 re 정규식으로 파싱하는 게 학습일지 형식 에 맞춰져 있었다. 내 블로그 글은 다른 구조 (frontmatter + 마크다운). 블로그 글에 맞는 파싱 으로 다시.
re 대신 frontmatter 라이브러리를 썼다. 마크다운 글의 메타데이터 (title, tags, pubDatetime) 와 본문을 깔끔히 분리.
파일명 / 제목 / 헤더 / 내용이 한 묶음으로 청크가 됐다. 여기서 청크들이 의미 단위로 잘 끊겼는지 확인하는 작업도 따로 필요 (지금은 일단 사이즈 기준).
4. 인덱스 빌드 — 청크 270개 임베딩
“인덱스를 빌드한다” 는 표현이 보였는데 임베딩이랑 비슷한 말인 것 같다. (실제로는 임베딩 생성 + 벡터 DB 에 적재 + 검색 인덱스 구축까지 묶은 용어)
약 1분에 청크 270개 생성. 이제 이걸로 Q&A 시스템.
5. Q&A 시스템 — OpenAI 임베딩 + Claude 답변
코드: blog_qa.py
여태까지 배운 내용들의 집합체:
- OpenAI API — 임베딩 (
text-embedding-3-small) - Claude API — 답변 생성
- Chroma — 벡터 검색
- 시스템 프롬프트 — “주어진 컨텍스트로만 답변. 모르면 모른다고.”
세 가지 질문으로 테스트.
질문 1 — “RAG 의 핵심 아이디어가 뭐야?”
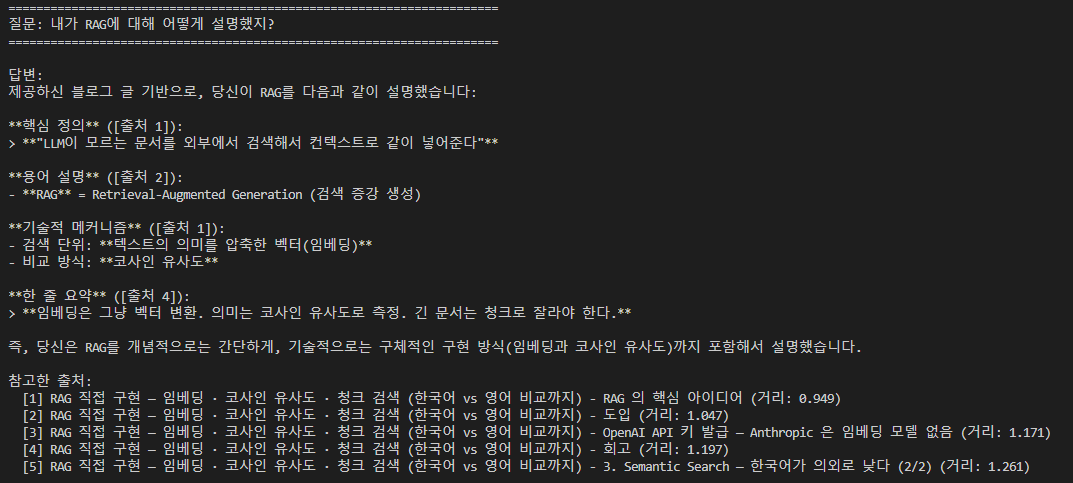
최근에 올린 RAG 기본 개념 글에서 잘 가져왔다. 정확한 청크에서 가져와서 유사도 점수도 높고 만족할만한 결과.
질문 2 — “Tool Use 학습에서 헤맸던 점은?”

이게 진짜 신기했다. 실제로 Tool Use 글 을 쓸 때 에러나 어려움이 없었어서, 회고는 했지만 헤맸던 건 안 적었다. 당연히 블로그 글에도 그 내용이 없는데, RAG 가 그걸 찾아내고 “블로그에서 찾을 수 없습니다” 라고 답변.
모르는 걸 모른다고 답하는 게 RAG 시스템의 가장 중요한 능력이다 (없는 답을 환각으로 만들지 않는 것).
질문 3 — “임베디드에서 AI Agent 로 전환한 이유는?”

현재 도메인이 정해진 게 아니고 둘 다 관심 이라서 “전환했다” 고 말한 적 없다. 당연히 그런 글도 없다. RAG 는:
- “임베디드 배경이 있다” 는 건 확인 ✓
- “AI 에이전트 쪽으로 전환한다는 얘기는 없다” 는 것까지 알아냄 ✓
다만 거리 값이 좀 높아서 검색 품질이 좋지 않을 수 있다 는 신호. 그래서 청크 사이즈를 줄여서 다시 해보기로.
회고
이번에 가장 크게 느낀 건 두 가지:
① 예제 학습법이 용어 정리보다 잘 들어온다
용어 정리 + 플레이그라운드 방식 (UI / DB / API) 도 괜찮지만, 이렇게 예제를 통해 배우는 게 훨씬 잘 이해되고 응용하고 싶은 마음 도 든다. 좋은 학습법.
② RAG 를 다른 제품에 붙이는 아이디어
이번 RAG 를 배우면서 떠오른 게 — 현재 dogfooding 중인 OneSmallThing (완벽주의자를 위한 작은 성취 기록 서비스) 에 붙이면 어떨까? 사용자의 일기를 RAG 코퍼스로 두고, 부정적 피드백이나 자신의 성취를 깎아내리는 패턴을 추적·분석 하는 데 도움될 수 있겠다 싶었다.
③ 개인용 LLM 만들기
Claude / OpenAI 같은 클라우드 API 가 나중에 토큰값이 비싸지거나, 한국에서 이용이 제한 될 수도 있다. 개인용 LLM (로컬 모델 + 자체 RAG) 을 구축해보는 프로젝트도 재밌을 것 같다.
더 공부해볼 것
1. Chroma 외 벡터 DB
- pgvector (Postgres + 확장) — Supabase 가 기본 지원, 기존 DB 와 통합
- Pinecone / Weaviate / Qdrant — 전용 호스팅 옵션
- FAISS (Facebook) — 라이브러리 형태, 가장 빠름
- 선택 기준: 데이터 양 / 호스팅 / 메타데이터 쿼리 필요 여부
2. 거리 메트릭 — L2 vs Cosine vs Inner Product
- L2 (Euclidean) — Chroma 기본. 두 벡터 사이의 직선 거리. 0 이 가깝고 클수록 멈
- Cosine — 어제 본 것. 각도. 1 이 가깝고 -1 이 반대
- Inner Product (Dot Product) — 정규화된 벡터에선 cosine 과 동일
- 임베딩 모델이 어떻게 학습됐는지에 따라 적합한 메트릭이 다름 (text-embedding-3 는 cosine 권장)
3. 청크 사이즈 / 오버랩 튜닝
- 작가 메모에서 짚은 것 — Q3 결과의 검색 품질이 낮아서 청크 사이즈 줄여본다
- Recursive Character Splitter (LangChain 표준) vs Semantic Chunking
- 오버랩 (sliding window) 으로 청크 경계에서 잘리는 문맥 보존
- 청크 사이즈 + 오버랩 조합으로 retrieval 품질 측정하는 방법 (recall@k 등)
4. Hybrid Search 도입
- 벡터 검색만으로는 고유명사·정확한 코드·오타 가 잘 안 잡힘
- BM25 (전통 키워드 검색) + 벡터 검색 결합
- Reciprocal Rank Fusion (RRF) 로 두 결과 순위 합치기
- Chroma 자체는 vector only, hybrid 가 필요하면 Weaviate / Qdrant 고려
5. 개인용 LLM — 로컬 RAG 스택
- Ollama (가장 진입 쉬움) — Llama 3 / Mistral / Qwen 등을 1줄로 실행
- llama.cpp + gguf 모델 — 양자화로 RAM 4~8GB 에서 동작
- 임베딩도 로컬 (
nomic-embed-text등) → 완전 오프라인 RAG - 답변 품질은 클라우드 LLM 보다 한 단계 낮지만 비용·검열·프라이버시 trade-off