지난 글 끝에 “다음 차시 Tool Use 들어가면 해보겠다” 고 적어뒀던 그 차시다. 직접 만져보니 단순한 “함수 호출 기능”이 아니라, LLM의 본질적 한계를 외부와 연결해서 메우는 메커니즘이었다.
Table of contents
Open Table of contents
LLM의 약점 두 가지
이번에 다시 명확해진 LLM의 한계:
- 큰 수의 정확한 계산 — 모델이 “847 × 2391” 같은 곱셈을 흉내내긴 하지만, 자릿수가 커질수록 환각(hallucination) 가능성이 커진다. 토큰 단위로 답을 생성하는 구조상 정확성을 보장하기 어렵다.
- 실시간 데이터 — 오늘 날짜, 오늘 주가, 지금 날씨 같은 정보는 모른다. 학습 시점의 스냅샷만 알고 있어서 그 이후의 사실은 모른다.
이건 단순히 “더 큰 모델을 만들자” 로 풀리는 문제가 아니다. LLM이 모든 것을 자기 안에 담을 수도 없고, 담아서도 안 된다. 그 자리에 등장하는 게 Tool Use.
Tool Use가 푸는 방식
모델에게 “너는 이런 함수들을 호출할 수 있어” 라고 알려준 뒤, 모델이 호출 의도를 내면 우리가 그 함수를 실제로 돌리고 결과를 다시 모델에게 돌려준다.
핵심은 모델이 직접 함수를 실행하지 않는다는 점. 모델은 “이 함수를 이런 인자로 호출해주세요” 라는 의도만 표현하고, 실제 실행은 클라이언트(내 코드) 가 한다. 안전·통제·검증의 책임이 우리 쪽에 남는다.
첫 실험 — calculator 도구
LLM이 산수를 못 한다고 가정하고, calculator(operation, a, b) 함수를 만들어 도구로 등록했다. 그리고 “847 × 2391은?” 이라고 물어봤다.
응답 블록 분석
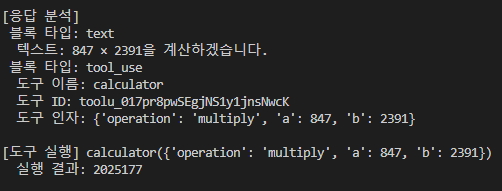
응답이 두 개의 블록으로 왔다.
블록 1 — type: text
내용: "847 × 2391을 계산하겠습니다."
블록 2 — type: tool_use
도구 이름: calculator
도구 ID: (이 호출을 식별하는 ID)
도구 인자: {"operation": "multiply", "a": 847, "b": 2391}그리고 내 코드에서 그 인자로 실제 calculator 를 실행하면 결과 2025177이 나온다.
흥미로운 건, 모델은 자체적으로도 곱셈을 시도할 수 있는데도, 도구가 등록되어 있으면 그쪽을 우선해서 사용한다는 점. 이게 의도된 동작이고, 그래서 도구의 등록만으로도 모델의 답변 신뢰도를 끌어올릴 수 있다.
메시지 흐름 — 가장 중요한 그림

Tool Use는 본질적으로 2턴짜리 대화다.
[1차 호출]
messages = [
{"role": "user", "content": "847 * 2391은?"}
]
+ tools = [calculator_tool]
↓
LLM 응답: tool_use 블록 (calculator, a=847, b=2391)
[본인 코드]
calculator(...) 실행 → 결과: 2025177
[2차 호출]
messages = [
{"role": "user", "content": "847 * 2391은?"},
{"role": "assistant", "content": [tool_use 블록]}, ← LLM의 1차 응답
{"role": "user", "content": [tool_result 블록]} ← 도구 실행 결과
]
↓
LLM 응답: "847 곱하기 2391은 2,025,177입니다"핵심 포인트.
- 1차 응답으로 도구 호출 의도를 받는다.
- 내가 도구를 실행한다.
- 실행 결과를
tool_result블록으로 묶어user메시지로 다시 보낸다. (도구 결과의 출처는 모델이 아니라 외부니까user측으로 들어간다) - 그러면 LLM이 그 결과를 받아 최종 답변(자연어)을 만든다.
이 구조는 멀티턴 글 의 “API는 stateless다, 클라이언트가 컨텍스트를 누적해서 보낸다” 와 정확히 같은 결의 패턴이다. 모델은 기억하지 않는다 → 호출자가 메시지 배열에 다 담아 다시 보낸다.
두 번째 실험 — 날씨 도구
같은 방식으로 get_weather(city) 함수를 만들어 도구로 등록했다. 예제에서는 더미 데이터로 응답하게 했지만, 실제로는 그 자리에 날씨 API 호출을 끼워 넣으면 LLM이 실시간 날씨를 답할 수 있게 된다.
즉, LLM은 학습 시점의 지식만 갖고 있어도 “도구를 통해 실시간 외부 세계와 연결” 되는 셈. Tool Use를 처음 본 인상의 핵심이 여기였다.
가장 신기했던 — 다중 도구 + 에이전트 루프
세 개의 도구(calculator, get_weather, get_time)를 동시에 등록해두고 사용자에게 자유롭게 질문하게 했다.
사용자: “지금 부산 날씨 알려주고, 그게 섭씨면 화씨로 바꿔서 알려줘.”
모델은 자동으로 순서대로 적절한 도구를 골라 호출했다.
- 먼저
get_weather(city="부산")호출 → 결과 받음 - 그 결과의 섭씨 값을 보고 →
calculator(...)호출해서 화씨 변환 - 두 결과를 종합해서 자연어 응답 생성
이걸 가능하게 한 게 에이전트 루프.
while True:
response = client.messages.create(
model=..., messages=messages, tools=tools
)
if response.stop_reason == "tool_use":
# tool_use 블록을 꺼내서 실제 함수 실행
for block in response.content:
if block.type == "tool_use":
result = execute(block.name, block.input)
# messages에 assistant tool_use + user tool_result 추가
...
continue # 다시 모델에게 보내서 다음 행동 받기
else:
# stop_reason == "end_turn" 이면 종료
breakstop_reason 이 "tool_use" 이면 도구를 더 쓸 차례이고, "end_turn" 이면 자연어 답이 완성된 것. 루프가 도구를 0번 ~ N번 돌릴 수 있다.
LLM이 자기에게 어떤 도구가 필요한지 판단해서 자동으로 선택한다는 점이 충격이었다. 내가 “이 질문엔 날씨를 먼저, 그 다음 계산기를” 같은 지시를 안 줬는데 알아서 그렇게 한다. 이게 에이전트(agent) 라는 단어의 본격적인 의미를 처음 체감한 순간.
정리
- LLM의 한계(큰 수 계산, 실시간 데이터) 를 외부 함수로 메우는 게 Tool Use.
- 모델이 직접 함수를 실행하지 않는다 — 호출 의도만 표현, 실제 실행은 클라이언트가.
- 메시지 흐름: 1차 호출 → tool_use 응답 → 함수 실행 →
tool_result를 user 메시지로 추가 → 2차 호출 → 자연어 응답. - 여러 도구를 등록하면 LLM이 알아서 필요한 도구를 골라 부른다. 이게 에이전트 루프.
더 공부해볼 것
1. Tool 정의 스키마
tools파라미터에 넘기는 JSON schema 형태 —name,description,input_schema각각의 역할- description을 잘 쓰는 게 왜 중요한지 (LLM이 도구를 고를 때의 근거가 됨)
input_schema의 required 필드, enum, nested object 처리- 참고: Anthropic Tool use 공식 문서
2. Tool Use 스트리밍 (이전 글에서 살짝 본 것)
- 지난 스트리밍 글 에서 본
input_json_delta청크들을 안전하게 누적해서 완전한 JSON 인자로 만드는 패턴 - 도구가 한 응답에서 여러 개 동시에 호출되는 경우(parallel tool use)의 이벤트 처리
3. 에이전트 루프의 안전장치
- 무한 루프 방지 (max iterations)
- 도구 실행 시간 제한 / 외부 API 실패 시 fallback
- 잘못된 도구 인자로 호출됐을 때 LLM에게 어떤 형태로 에러를 돌려줘야 다음 시도가 똑똑해지나
- 도구 결과가 너무 길 때 컨텍스트 관리 (요약? 자르기?)
4. 도구 선택 정확도 측정
- 같은 질문을 100번 던졌을 때 LLM이 매번 같은 도구를 고르는가
- 도구 description을 조금만 바꿔도 선택 결과가 어떻게 흔들리는지
- 도구가 많아질수록 (5개 → 20개) 정확도가 어떻게 변하는가
5. Tool Use vs Function Calling vs Plan & Execute 패턴
- 다른 LLM 제공자(OpenAI 등)의 Function Calling과 비교
- 더 큰 그림: ReAct, Plan-and-Solve, OpenAI Assistants API 같은 에이전트 패턴들과 Tool Use의 관계
- 참고: Anthropic Building effective agents
6. 직접 만들어볼 거리
- 날씨 도구를 실제 API(OpenWeather 등)에 연결해서 실시간 날씨 답변
- 내 Supabase DB 쿼리 도구를 만들어서 “어제 가입한 사용자 수 알려줘” 같은 자연어 질문에 답하게 하기
- 도구 실행 결과를 캐시해서 같은 질문에 반복 호출 안 하도록 최적화
회고
Tool Use를 만지고 나서, 에이전트(agent) 라는 단어의 무게가 비로소 체감됐다. 그동안은 “AI가 자동으로 뭐 한다” 정도의 모호한 감각이었는데, 직접 도구를 등록해두고 LLM이 그것들을 골라 쓰는 모습을 보니 — “LLM = 의사결정자, 외부 도구 = 실행 능력” 이라는 분업 구조가 명확해졌다.
내가 진행 중인 1인 앱에도 이걸 끼울 자리가 보인다. Supabase DB 조회나 외부 API 호출을 Tool Use로 묶고, 자연어로 그걸 부르는 인터페이스를 얹으면, 단순한 챗봇이 아니라 진짜로 사용자 의도를 행동으로 옮기는 에이전트 가 된다. 다음 학습은 이 방향을 직접 짜보는 쪽으로 가야겠다.