Claude API로 간단한 챗 시스템을 만들면서 “왜 모델이 직전 대화를 기억하지 못하지?” 라는 질문을 직접 부딪히며 풀어봤다.
Table of contents
Open Table of contents
실험 설계
같은 대화 흐름을 두 가지 방식으로 돌려봤다.
- 방식 A — 히스토리 누적: 매 턴마다
messages배열에 user / assistant 메시지를 모두 누적해서 API에 전달 - 방식 B — 매번 새 배열: 매 턴마다 새로운
messages배열을 만들어 보냄 (직전 user 메시지만 들어감)
대화 시나리오는 동일하다.
You: 안녕. 내 이름은 박효인이야.
Claude: 안녕하세요, 박효인님!
You: 내 이름이 뭐였는지 기억나?결과
방식 A — 잘 기억한다
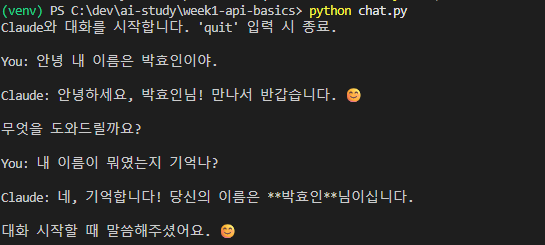
Claude: 네, 기억합니다! 당신의 이름은 박효인님이십니다. 대화 시작할 때 말씀해주셨어요. 😊
방식 B — 전혀 기억하지 못한다
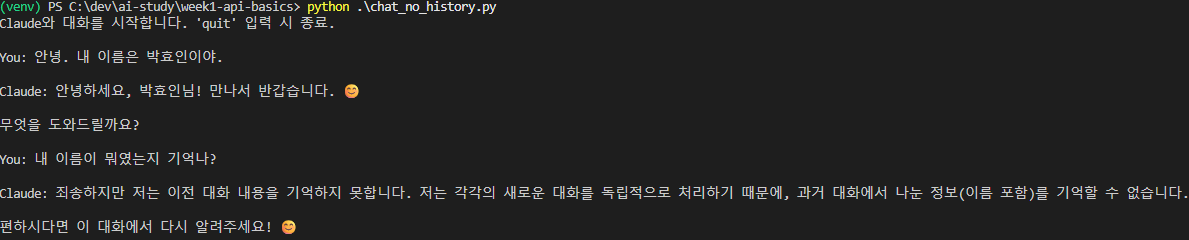
Claude: 죄송하지만 저는 이전 대화 내용을 기억하지 못합니다. 저는 각각의 새로운 대화를 독립적으로 처리하기 때문에, 과거 대화에서 나눈 정보(이름 포함)를 기억할 수 없습니다.
같은 모델, 같은 프롬프트인데 결과가 정반대다.
핵심 — Claude API는 stateless다
API 자체에는 “세션”이라는 개념이 없다. 매 요청은 독립적이다. 모델이 직전 대화를 “기억”하는 것처럼 보이는 건, 클라이언트(내 코드)가 매 요청마다 과거 메시지를 통째로 다시 같이 보내고 있어서다.
즉 모델이 기억하는 게 아니라, 내가 매번 과거를 다시 알려주는 것.
# 방식 A — 누적
messages = []
while True:
user_input = input("You: ")
messages.append({"role": "user", "content": user_input})
response = client.messages.create(
model="claude-opus-4-5",
max_tokens=1024,
messages=messages,
)
assistant_text = response.content[0].text
messages.append({"role": "assistant", "content": assistant_text})
print(f"Claude: {assistant_text}")핵심은 messages.append({"role": "assistant", ...}) 한 줄이다. assistant 응답을 다음 턴의 입력 배열에 다시 넣어주기 때문에, 모델 입장에서는 “이전에 내가 이렇게 말했었구나”를 매번 처음부터 다시 읽는 것이다.
실험에서 추가로 느낀 것
1. 매 턴마다 input_token이 비싸진다
대화가 길어질수록 messages 배열도 커지고, 매 요청에 보내는 토큰 수가 누적된다. 100턴 대화라면 100번째 요청은 앞 99턴의 user/assistant 텍스트를 모두 다시 보낸다. 사실상 비용이 대화 길이에 비례해서 폭발적으로 늘어난다.
→ 컨텍스트 관리가 필요하다. 무한정 누적하면 안 되고, 어느 시점에서 압축하거나 잘라내야 한다. 이건 별도 학습 거리.
2. 시스템 프롬프트의 유무에 따라 응답 톤이 확연히 다르다
system 파라미터에 페르소나/규칙을 명시했을 때와 그렇지 않을 때, 모델의 답변 스타일이 눈에 띄게 달라졌다. 시스템 프롬프트는 단순한 “성격 설정”이 아니라 응답의 출발점 자체를 바꾸는 강력한 레버라는 인상을 받았다.
더 공부해볼 것
이번 실험으로 멀티턴 동작 원리는 이해했지만, 실전에서 마주칠 다음 단계 주제들.
1. Context window와 토큰 관리
- Claude의 컨텍스트 윈도우 한계 (모델별로 다름)
- 대화가 한계에 가까워졌을 때 전략: 오래된 메시지 truncate / 요약(summarization) / 슬라이딩 윈도우
- 토큰 사용량을 미리 계산하는 방법 — Anthropic SDK의 token counting API
- 참고: Anthropic Docs — Building with Claude
2. Prompt Caching — 비용 줄이는 핵심 기법
긴 시스템 프롬프트나 누적되는 메시지 히스토리를 캐시로 표시하면, 같은 프리픽스를 재사용하는 후속 요청에서 토큰 비용을 크게 줄일 수 있다.
cache_control마커 사용법- 캐시 히트율을 높이는 메시지 배치 전략 (안정적인 부분을 앞에, 변동 부분을 뒤에)
- 멀티턴 챗봇에 적용했을 때 비용/지연 변화
- 참고: Anthropic 공식 문서의 Prompt Caching 섹션
3. 시스템 프롬프트 설계
system파라미터의 역할 — user 메시지와 어떻게 다른가- 페르소나 / 작업 지시 / 출력 형식 규칙을 한 시스템 프롬프트에 어떻게 분리해서 담을지
- few-shot 예시를 시스템 프롬프트에 넣는 게 좋은가, user/assistant 페어로 넣는 게 좋은가
4. Stateful한 대화를 만드는 다른 방법
- 외부 저장소(DB / 파일)에 대화 로그를 적재하고, 사용자가 돌아왔을 때 다시 messages로 복원
- “메모리”를 갖는 에이전트 패턴 — 중요한 사실만 추출해서 별도 메모리에 저장하고 시스템 프롬프트에 주입
- Anthropic의 Memory tool이나 Files API 같은 상위 기능 활용
5. 직접 비교해볼 것
- 방식 A에서 대화가 길어질수록 응답 품질이 어떻게 변하는가 (긴 컨텍스트의 attention 분포)
- 시스템 프롬프트 vs. 첫 user 메시지로 같은 지시를 줬을 때 응답 차이
- 같은 입력에 대해 모델 버전(Opus / Sonnet / Haiku)별 token 비용·지연·품질 비교
회고
“모델이 기억하지 못한다” 는 말은 정확하지 않다. 정확히는 API 호출 사이에 상태가 보존되지 않는다. 기억의 책임은 모델이 아니라 클라이언트 쪽에 있고, 그 책임을 어떻게 효율적으로 지느냐(컨텍스트 관리, 캐싱, 외부 메모리)가 LLM 애플리케이션 설계의 핵심 같다.
다음 실험은 prompt caching으로 같은 챗 시스템의 비용을 얼마나 줄일 수 있는지 측정해보는 것.