스트리밍 글 끝의 “공부할 것” 에 적어둔 Prompt Caching 차례. 직접 같은 시스템 프롬프트로 캐싱 유무를 비교해보니 인상이 명확해졌다. 결론부터: 챗봇 / 에이전트 / RAG에는 거의 필수.
Table of contents
Open Table of contents
한 줄 요약
같은 내용을 반복해서 LLM에 보낼 때, 두 번째부터는 거의 공짜로 처리해주는 기능.
왜 캐싱이 필요한가
LLM은 입력을 받으면 컴퓨팅 비싼 전처리를 내부적으로 수행한다. 같은 입력에 대해 매번 이 작업을 반복하는 건 그대로 낭비. 캐싱을 켜면 서버 쪽에 처리 결과를 보관해뒀다가 다음 호출에서 재사용한다.
효과가 큰 시나리오 4가지
- 긴 시스템 프롬프트 가 매 호출마다 똑같을 때
- 긴 문서를 컨텍스트로 넣고 여러 질문 할 때 (RAG)
- 멀티턴 대화 에서 이전 히스토리가 길 때
- 도구 정의가 많을 때 (에이전트)
내가 진행 중인 1인 앱 / 자율주행 사이드 프로젝트의 챗봇 모듈에 다 해당하는 패턴이라 더 관심이 갔다.
가격 구조

| 항목 | 단가 (Haiku 4.5 기준) | 비율 |
|---|---|---|
| 일반 input | $1 / M 토큰 | 1x |
| Cache write (첫 캐싱 시) | $1.25 / M | 1.25x — 살짝 비쌈 |
| Cache read (두 번째부터) | $0.10 / M | 0.1x — 90% 할인 |
핵심: 첫 호출은 살짝 비싸고(1.25x), 두 번째부터 90% 싸진다(0.1x). 즉 2번 이상 같은 컨텍스트를 보낼 거면 무조건 이득.
비용 시뮬레이션
같은 컨텍스트(1 단위) 를 N 번 보낼 때의 누적 비용:
| 호출 횟수 | 캐싱 없음 | 캐싱 있음 | 절감 |
|---|---|---|---|
| 1회 | 1.00x | 1.25x | (살짝 손해) |
| 2회 | 2.00x | 1.35x | −32% |
| 3회 | 3.00x | 1.45x | −52% |
| 10회 | 10.00x | 2.15x | −78% |
호출이 많아질수록 절감 폭이 빠르게 커진다. 3번 이상 보낼 거면 캐싱이 거의 항상 이득.
캐시는 영원하지 않다 — TTL
캐시는 기본 5분 유지, 옵션으로 1시간 까지 늘릴 수 있다고 한다. 5분 안에 후속 호출이 오면 cache read 가격으로 처리되고, 지나면 만료돼서 다시 cache write 부터 시작.
→ 연속 사용 흐름이 끊기지 않는 챗봇 / RAG / 에이전트에 자연스럽게 맞고, 띄엄띄엄 호출되는 워크로드에는 효과가 떨어진다.
함정 — 최소 토큰 수 제한
캐시를 쓰려면 일정 크기 이상의 입력 이 필요하다. 작은 입력은 캐싱 대상조차 안 됨.
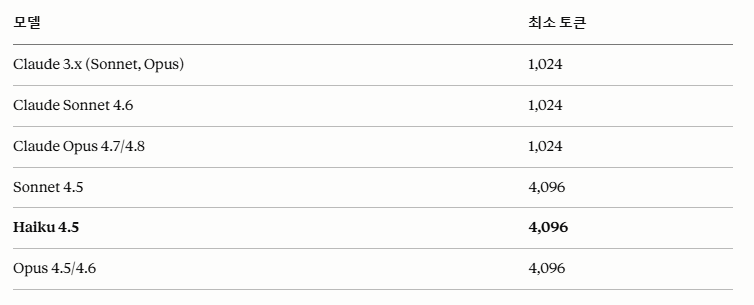
| 모델 | 캐시 사용 최소 토큰 |
|---|---|
| Claude 3.x (Sonnet, Opus) | 1,024 |
| Claude Sonnet 4.6 | 1,024 |
| Claude Opus 4.7 / 4.8 | 1,024 |
| Sonnet 4.5 | 4,096 |
| Haiku 4.5 (내가 사용) | 4,096 |
| Opus 4.5 / 4.6 | 4,096 |
첫 실험에서 시스템 프롬프트가 짧아서 캐싱이 무시됐다. 모델별 최소 토큰을 미리 확인하고, 부족하면 시스템 프롬프트에 의도적으로 안내문이나 예제를 채워야 한다.
직접 실험 — A vs B
같은 시스템 프롬프트(임베디드 도메인 컨텍스트)를 깔고 3개 질문을 던졌다. 한 번은 캐싱 없이, 한 번은 캐싱 켜서.
질문 예시:
- “Cortex-M4와 M7의 가장 큰 차이가 뭐야?”
- “FreeRTOS에서 우선순위 역전 어떻게 방지해?”
- “STM32에서 DMA 사용할 때 주의사항은?”
실험 A — 캐싱 없음
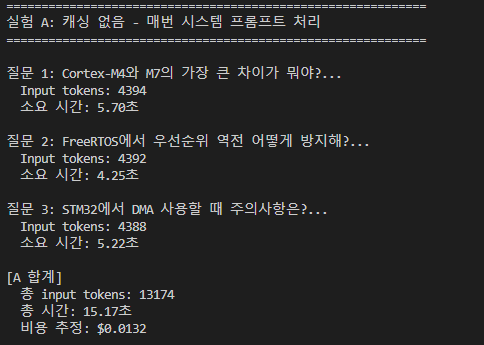
- 매 질문마다 시스템 프롬프트 전체를 처리 → input 약 4,390 토큰 × 3회 = 13,174 토큰
- 총 시간 15.17초
- 비용 $0.0132
실험 B — 캐싱 사용

- 첫 질문: Normal input 32 + Cache write 4,362 (이 시점이 가장 비쌈)
- 두 번째·세 번째 질문: Normal input 30/26 + Cache read 4,362 / 4,362 (이게 거의 공짜)
- 총 시간 14.07초
- 비용 $0.0064
비교 결과
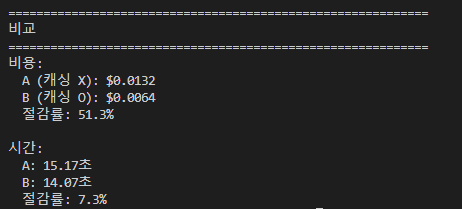
| 지표 | 캐싱 X | 캐싱 O | 절감 |
|---|---|---|---|
| 비용 | $0.0132 | $0.0064 | −51.3% |
| 시간 | 15.17초 | 14.07초 | −7.3% |
비용은 절반, 시간은 미미하게. 이게 정직한 결론. Prompt caching 의 본질은 TTFT 개선이 아니라 token 비용 최적화다. (TTFT를 깎는 건 스트리밍 의 영역이고, 두 도구가 보완 관계.)
시행착오 모음
직접 만져보면서 부딪힌 함정들.
- 최소 토큰 미달: Haiku 4.5 는 4,096 토큰 이상이어야 캐시 적용. 부족하면 그냥 무시됨 (에러도 안 남, 조용히 일반 input 가격으로 처리)
- 1바이트라도 다르면 캐시 미스: 시스템 프롬프트에 timestamp 같은 동적 값을 섞으면 매번 새 캐시 → 의미 없음. 고정 부분은 한 덩어리로 묶고, 동적 부분은 분리해서 user 메시지 쪽으로 빼야 함.
- 5분 만료: 사용자가 잠시 자리를 비웠다 돌아오면 캐시 만료 → 다음 호출은 cache write 부터. 비용 모델 설계 시 반영해야 함.
- 잘 작동하는 패턴: “긴 고정 부분 + 짧은 동적 부분” — 시스템 프롬프트는 고정해서 캐시, user 메시지로 turn 마다 변하는 부분만 보내기.
실험 코드
전체 비교 코드는 GitHub 에 올려뒀다: github.com/dpcivl/ai-study-week1/blob/main/prompt_caching.py.
cache_control 마커를 시스템 프롬프트 블록에 붙이는 것 외에 클라이언트 코드는 거의 그대로다. 한 줄 추가로 비용을 절반으로 줄일 수 있다는 게 핵심.
더 공부해볼 것
1. 다중 캐시 블록 / 캐시 계층
- 시스템 프롬프트 + 도구 정의 + RAG 문서를 각각 다른 cache_control 마커 로 따로 캐싱하면 어떤 차이가 있는지
- 한쪽이 만료돼도 나머지는 살아있게 분리하는 패턴
2. 1시간 TTL 옵션
- 5분 vs 1시간 옵션의 가격 차이 (있다고 들음)
- 어떤 워크로드에 1시간이 이득인가 (예: 매시간 한 번 도는 cron, 일과 시간 챗봇)
3. 멀티턴 챗봇 + 캐싱 통합
- 멀티턴 글 의 messages 누적 패턴에 캐싱을 얹는 법
- 누적되는 history 중에서 어디까지를 캐시 블록으로 묶을지 (안정적 prefix vs 변동 suffix)
4. Tool Use 에이전트 + 캐싱
- Tool Use 글 의 에이전트 루프에서 도구 정의를 캐싱
- 에이전트가 도구를 N 번 호출할 때 매번 도구 정의 전체를 보내야 하는 비용을 캐시로 상쇄
5. 직접 측정해볼 다음 단계
- 시스템 프롬프트 길이를 4k → 8k → 16k 로 늘리면 절감률이 어떻게 변하는가
- 캐시 read 의 응답 지연(latency)이 정확히 얼마나 짧아지는가 — 이번 실험은 7.3% 였지만 더 긴 프롬프트면 차이가 클 가능성
- 1인 앱의 Supabase Edge Functions 에서 호출할 때 cold start + 캐시 만료가 어떻게 상호작용하는지
회고
LLM 비용 최적화의 첫 번째 도구로 prompt caching 이 거론되는 이유를 직접 만져보고 확실히 이해했다. “한 줄 마커 추가로 비용 절반” 이 과장이 아니라 실제로 그렇다.
다만 함정도 분명하다 — 최소 토큰 미달이면 조용히 무시되고, 시스템 프롬프트에 동적 값이 섞이면 캐시 미스 폭탄이고, 5분 TTL 이라 띄엄띄엄 호출되는 워크로드엔 효과가 떨어진다. 도구 자체의 효과만큼 도구가 가진 제약을 같이 익히는 게 실전 적용의 핵심.
다음에는 멀티턴 글 의 챗봇 예제를 캐싱 적용 버전으로 업그레이드해서, “히스토리가 누적될수록 비용은 어떻게 변하는가” 를 실측해볼 예정.