새 시리즈 시작. 퀀트 (quantitative trading) 공부. 00 은 도구·개념 기초편. 직접 백테스트 코드를 굴리기 전에 pandas 가 시계열 데이터를 어떻게 다루는지 + 백테스트가 자주 거짓말하는 4가지 패턴 을 먼저 정리.
Table of contents
Open Table of contents
1. pandas 기초 — Series 와 DataFrame
- Series = 1차원 (한 줄)
- DataFrame = 2차원 (표)
종가 시계열 한 줄은 Series, OHLCV (시가·고가·저가·종가·거래량) 표는 DataFrame.
loc vs iloc — 라벨이냐 위치냐
| 기준 | 예시 | |
|---|---|---|
loc | 라벨 (날짜, 컬럼명) | df.loc["2026-06-01", "Close"] |
iloc | 위치 (정수 인덱스) | df.iloc[0, 3] |
시계열에서는 보통 loc 로 날짜 슬라이싱하는 경우가 많고, “마지막 N 일” 같은 상대적 접근에는 iloc 가 편하다.
2. pandas 는 과거를 본다 — 워밍업 구간 (NaN)
이동평균 같은 롤링 윈도우 연산 은 과거 N 개의 값 이 있어야 계산이 된다. 그런데 시계열 맨 앞은 과거가 없다.
- 20일 이동평균 → 1일째에는 과거 20개가 없으니
NaN - 이 구간이 “워밍업”
처리법:
df["MA20"] = df["Close"].rolling(20).mean()
df = df.dropna() # NaN 행 제거 → 워밍업 잘라내기dropna() 는 “NaN 이 아닌 값만” 남기는 메서드. 워밍업을 안 잘라내면 뒤따라오는 시그널 계산이 죄다 NaN 으로 오염된다.
3. 조용한 데이터 오염 — 수정주가의 함정
같은 종목, 같은 기간을 불러도 다음에 받을 때 데이터 자체가 바뀌어 있을 수 있다. 액면분할, 배당, 유상증자가 일어나면 과거 종가까지 소급해서 재조정 되기 때문 (이게 “수정주가” / adjusted close).
문제는 이게 에러를 일으키지 않는다. 그냥 숫자가 살짝 달라질 뿐. 그래서 어제 잘 돌던 백테스트가 오늘 갑자기 다른 결과를 뱉으면 한참 헤맨다.
대응:
use_cache=False로 캐시 강제 새로 받기- 분할/배당 이벤트가 있었던 종목은 캐시 파일을 지우고 다시 받기
코드 버그보다 데이터 버그 가 더 무섭다. 에러 없이 수익률만 살짝 부풀어 보이는 식.
4. 전략 분류 — 추세추종 vs 평균회귀
같은 가격 차트를 봐도 시장 국면 에 따라 정반대 전략이 작동한다.
추세추종 (Trend Following)
“오르는 건 더 오른다”
- 대표 지표: 이동평균 (MA), TSMOM (Time-Series Momentum)
- 신호: 골든 크로스 (단기 MA 가 장기 MA 를 위로 뚫음) → 매수
- 신호: 데드 크로스 (단기 MA 가 장기 MA 를 아래로 뚫음) → 매도
- 추세장 에서 잘 먹힘
평균 회귀 (Mean Reversion)
“빠진 건 제자리로 돌아온다”
- 대표 지표: RSI, 볼린저 밴드
- 신호: 평균에서 많이 벗어났을 때 반대 방향 진입
- 횡보장 에서 잘 먹힘
핵심
현재 시장이 추세장인지 횡보장인지에 따라 전략을 바꿔야 한다. 추세장에 평균회귀를 돌리면 계속 칼날을 잡고, 횡보장에 추세추종을 돌리면 잦은 손절로 갈린다.
5. 워밍업 길이가 다르면 결론도 거짓말한다
전략 A 는 20일 MA, 전략 B 는 200일 MA 를 쓴다고 하자. 두 전략을 같은 기간으로 비교하면 워밍업이 다르다:
- A 는 21일째부터 신호 발생
- B 는 201일째부터 신호 발생
A 의 처음 180일 거래가 B 에는 아예 없는 것 이라, 같은 성과를 봐도 출발선이 다르다. 공정한 비교를 하려면 가장 긴 워밍업 기준으로 두 전략 모두를 잘라야 한다.
워밍업 정렬 안 하면 잘못된 결론으로 직행.
6. 퀀트의 4대 편향 — 백테스트가 거짓말하는 4가지 방식
(1) 미래참조 편향 (Look-ahead Bias)
그 시점에 못 보는 미래 데이터로 결정 을 내리는 실수.
- 예: t 일의 종가로 t 일의 매수 결정 (종가는 장 끝나야 확정인데 장중에 알 수 있다고 가정)
- 예: t+1 일의 시초가로 백테스트하면서 “t 일 종가 보고 결정한 척”
방지 핵심 = 시간 경계. 신호 계산은 t-1 이전 데이터로만, 거래는 t 일에.
(2) 과최적화 (Overfitting)
파라미터를 과거에 너무 잘 맞춰서 미래에는 무너지는 결과.
- 예: “MA 17일선 + RSI 6 + 볼린저 1.8σ” 가 2020~2025 에 환상적이었음 → 2026 에서 와장창
- 과거에 매끄럽게 떨어지는 조합은 데이터에 끼워맞춘 것 일 가능성 높음
Out-of-sample 테스트 로 어느 정도 거를 수 있음.
(3) 비현실적 거래비용
수수료·세금·슬리피지를 무시하면 종이 위의 수익률은 마법처럼 좋아진다. 특히 거래 빈도가 높은 전략은 거래비용 차감 후 손익 부호가 뒤집히는 경우도 흔함.
(4) 생존편향 (Survivorship Bias)
살아남은 종목만 보면 망한 패자가 빠진다. 현재 시점의 종목 리스트로 과거 수익률을 계산하면, 이미 상장폐지된 망한 회사들은 데이터셋에 없다. 그래서 다 성공한 케이스만 다루게 되고 수익이 실제보다 부풀려진다.
“백테스트가 너무 좋으면 의심하라.” 4대 편향 중 하나에 걸려 있을 확률이 높다.
생존편향 누수 측정 — 직접 부활시키기
내 백테스트에 생존편향이 얼마나 끼었는지 확인하려면:
누수 = (유니버스에 든 상폐 종목 수) - (그중 size 랭킹에 실제로 들어간 수)이 차이가 클수록 망한 패자가 size 명단에서 많이 빠진 것 = 생존편향 누수 큼.
7. 한 점이 아니라 분포로 봐야 한다 — 가짜 알파 거르기
백테스트 결과를 단 한 번의 수익률 곡선 으로 판단하면 위험하다. 같은 전략을 파라미터/기간을 살짝만 바꿔도 결과가 출렁이기 때문. 그래서 한 점이 아니라 분포 를 본다.
“이 전략이 B&H 를 이겼나” (한 점) 가 아니라 “여러 조건에서 돌렸을 때 알파 중앙값이 양수인가, 노출시간 대비 합리적인가” (분포)
“가짜 알파” 의 함정
B&H 초과 비율 (beat rate) 이 높아도 가짜 알파일 수 있다. B&H 는 그냥 사놓고 가만히 있는 단순 매수후 보유 전략. 이걸 자주 이겼다고 좋은 게 아니다. 같이 봐야 하는 두 가지:
- Alpha 중앙값 — 평균이 아니라 중앙값. 한두 번 크게 터진 거래가 평균을 끌어올리는 경우가 흔하다. 중앙값이 음수면 거래 절반 이상이 손실 → 실매매에선 일반적인 거래가 손해.
- 노출시간 (Market Exposure) — 전체 기간 중 포지션을 들고 있던 시간의 비율. 5% 만 시장에 노출하고도 B&H 를 이겼다면 그건 단순 비교가 불공정한 것 (대부분 시간 현금이라 변동성이 낮을 수밖에). 노출시간이 짧을수록 표본이 적어 운으로 이긴 것일 확률 이 높다.
B&H 초과 비율만 보면 좋아 보여도, 노출시간이 짧고 Alpha 중앙값이 음수 인 케이스가 의외로 많다. “이긴 적이 많다” 와 “꾸준히 이긴다” 는 다른 얘기.
워크포워드 (Walk-forward Analysis)
과최적화를 거르는 표준 방법. 한 번 잡은 파라미터를 고정해놓고 시계열을 앞으로 밀면서 그 다음 구간에서도 통하는지 본다.
[ in-sample : 파라미터 최적화 ] → [ out-of-sample : 그 파라미터로 검증 ]
↓ (앞으로 밀기)
[ in-sample ] → [ out-of-sample ]
↓
...- in-sample 에서 화려, out-of-sample 에서 무너짐 → 과최적화 신호
- out-of-sample 결과 분포 를 봐야 진짜 알파 여부 판단 가능
여기서도 다시 분포 가 등장. 한 번의 out-of-sample 결과가 좋다고 좋은 전략이 아니라, 여러 윈도우로 슬라이딩한 결과의 중앙값/분산 이 양호해야 한다.
회고 — “느낌으로 벤치마킹” 하는 습관을 발견
이번 학습하면서 자꾸 벤치마킹을 느낌으로 하는 경향 이 스스로 있다는 걸 깨달았다. “캐시 쓰면 빠르긴 한 거 같은데…” 같은 식.
예제에서 시간을 직접 재서 수치화 해봤다:
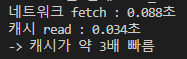
- 네트워크 fetch: 0.088 초
- 캐시 read: 0.034 초
- 캐시가 약 3배 빠름
“3배” 라는 숫자가 손에 들어오니까 비로소 “캐시는 쓰는 게 맞다” 가 판단 이 된다. 그 전엔 그냥 인상이었음. 퀀트는 결국 숫자로 의심하고 숫자로 결정 하는 분야니까 이 습관부터 고쳐야 할 듯.
더 공부해볼 것
1. pandas 시계열 도구
resample()— 일봉 → 주봉 / 월봉 변환shift()— 미래참조 방지에 필수 (signal = df["Close"].shift(1) > df["MA20"].shift(1))rolling()의min_periods옵션 — 워밍업 제어- MultiIndex — 종목 × 날짜 패널 데이터
2. 백테스팅 프레임워크
- backtrader / vectorbt / zipline / bt — 직접 구현 vs 프레임워크
- 직접 구현이 학습엔 좋지만 4대 편향 방지는 프레임워크가 더 안전
- Walk-forward optimization, anchored / rolling 윈도우
3. 4대 편향 방지 도구
- Point-in-time (PIT) 데이터 — 그 시점에 알려졌던 그대로의 데이터 (재무제표 재공시 반영 X)
- Survivorship-bias-free 데이터셋 — 상폐 종목까지 포함된 유니버스 (CRSP 같은 상용 데이터)
- Combinatorial Purged CV (Marcos López de Prado) — 시계열 K-fold 의 누수 방지
4. 시장 국면 판별 (Regime Detection)
- 추세장 / 횡보장 자동 판별 → 전략 자동 스위칭
- ADX, Hurst exponent, HMM (Hidden Markov Model)
- 단일 전략보다 “국면 인식 + 전략 라우팅” 이 실전적
5. 거래비용 모델링
- 수수료 (정률) + 세금 (양도세, 거래세) + 슬리피지 (시장 충격)
- 슬리피지는 거래량 대비 주문량에 비례 → 자산 규모가 커질수록 무시 못 함
- 거래비용 차감 후 Sharpe 가 1 미만이면 실전 적용 보류