임베디드 환경에서 객체 인식을 했던 이전 경력을 살려 NDT(Non-Destructive Testing, 비파괴 검사) 분야에 다시 도전해볼 기회가 생겼다. 이를 계기로 며칠 동안 NDT 도메인을 다시 잡고 작은 실습 프로젝트를 돌렸다. PyTorch + ResNet18 전이학습으로 강철 표면 결함 6종을 분류하고, Grad-CAM으로 모델이 어디를 보고 판단하는지까지 확인한 전체 파이프라인.
Table of contents
Open Table of contents
진행 순서
- 환경 설정 및 데이터 다운로드
- 데이터 탐색 (EDA)
- 데이터 전처리 및 증강
- 분류 모델 학습 (ResNet18 전이학습)
- 평가 및 시각화 (Confusion Matrix + Grad-CAM)
- 모델 저장 및 추론 성능 측정
1. 환경 설정과 데이터 준비
프레임워크는 PyTorch를 사용했다. 나는 주로 TensorFlow를 써왔지만, NDT 도메인의 최신 자료와 NEU 데이터셋 예제가 PyTorch 기반이 많아 이번 기회에 PyTorch를 직접 만져봤다.
샘플 코드의 데이터셋 경로 자동 다운로드가 잘 동작하지 않아서, Kaggle에서 NEU Surface Defect Dataset을 직접 다운로드 했다.
💡 NEU = 중국 동베이대학교(Northeastern University, China). 데이터셋 이름의 출처가 궁금해서 찾아봤더니 그냥 학교명 약자였다.
데이터셋은 강철 표면 결함을 다음 6가지로 분류한다.
- Crazing (Cr) — 균열 모양 결함
- Inclusion (In) — 이물질 포함
- Patches (Pa) — 패치형 얼룩
- Pitted Surface (PS) — 핏팅 부식
- Rolled-in Scale (RS) — 압연 스케일
- Scratches (Sc) — 스크래치
2. PyTorch Dataset 클래스 정의 — 데이터 라벨링이 모델 성능의 첫 단추
PyTorch에서 커스텀 데이터셋을 만들려면 __len__(전체 샘플 수)과 __getitem__(인덱스로 한 샘플 꺼내기) 두 메서드를 구현하면 된다. 그러면 DataLoader가 그 객체를 받아 배치 묶기, 셔플, 병렬 로딩을 자동으로 처리해준다.
이번 실습에서 신경 쓴 두 가지:
명시적 매핑 — 파일명 파싱 대신 폴더 구조
NEU 데이터셋은 파일명 접두사로도 클래스를 구분할 수 있지만, 폴더 구조(train/images/crazing/...)로 클래스를 구분하는 방식을 택했다. 파일명 파싱은 규칙이 어긋난 파일 하나만 들어와도 엉뚱한 라벨로 학습된다. 폴더로 구분하면 그런 위험이 사라지고, 새 클래스를 추가하기도 쉽다.
클래스 → 인덱스 매핑
분류 모델은 클래스를 정수로 학습한다. 따라서 클래스를 정렬해 번호를 매기고, 예측 결과를 다시 사람이 읽을 수 있는 라벨로 역변환하는 매핑이 필요하다.
class_to_idx = {"crazing": 0, "inclusion": 1, "patches": 2, ...}
idx_to_class = {v: k for k, v in class_to_idx.items()}os.walk 로 폴더를 훑으면서 클래스 폴더에 속한 이미지만 수집했고, 샘플이 0개인 경우 명시적으로 에러를 띄우는 방어 로직도 같이 넣어뒀다. 데이터 로드 실패는 빠르게 시끄럽게 알리는 게 디버깅에 훨씬 좋다.
3. EDA — 사람 눈으로 먼저 확인하기
본격적인 학습 전에 데이터 탐색(EDA)을 한다. 각 클래스의 샘플 이미지를 그리드로 시각화해서 다음을 확인한다.
- 클래스끼리 사람 눈에도 구분되는가? 사람이 못 가르면 모델도 어렵다.
- 데이터에 인공물(label noise, 잘못 들어간 이미지)은 없는가?
- 데이터 파이프라인이 정상적으로 도는가? (
__getitem__이 의도대로 동작하는지)

각 클래스의 시각적 특징이 분명히 다르다는 걸 확인했다. 모델이 학습할 만한 분리도가 있다는 신호.
4. 데이터 전처리 및 증강 — NDT 데이터의 특수성
NDT 데이터는 일반적으로 결함 클래스에 비해 정상 샘플이 압도적으로 많은 불균형을 보인다. 또 데이터 수집 자체가 비싸기 때문에 데이터 증강(augmentation) 으로 일반화 성능을 끌어올린다.
증강 전략 — 어떤 변형이 안전한가
NDT에서 증강을 고를 때의 핵심 기준: 결함의 본질적 특성을 왜곡하지 않을 것.
| 증강 종류 | NDT에서 적합한가 |
|---|---|
| 회전 / 좌우·상하 반전 | ✅ — 결함은 방향과 무관 |
| 약한 밝기 조정 | ✅ — 조명 조건 변동을 시뮬레이션 |
| 강한 색상 변경 / 톤 시프트 | ⚠️ — 결함의 시각적 특성을 왜곡 |
| 강한 왜곡 / 큰 노이즈 추가 | ❌ — 결함의 본질을 흐림 |
증강이 학습 데이터셋에서만 의미가 있는 이유
같은 학습 이미지여도 매 epoch마다 다르게 변형되어 들어가기 때문에, 모델 입장에서는 사실상 더 다양한 데이터를 본 셈이 된다. 그래서 증강은 학습 셋에만 적용하고 검증/테스트 셋에는 적용하지 않는다.
5. 전이학습 — ResNet18 가중치 재활용
처음부터 모델을 학습시키려면 데이터가 아주 많이 필요하다. 전이학습(Transfer Learning) 은 이미 큰 데이터로 학습된 모델의 가중치를 출발점으로 삼고, 마지막 분류기 층만 우리 문제에 맞춰 다시 학습시킨다.
이번엔 ImageNet으로 학습된 ResNet18을 가져왔다. 그 모델은 이미 다양한 시각 패턴(에지, 텍스처, 모양 조합)을 학습해뒀기 때문에, 출력층(nn.Linear)만 6 클래스로 교체하면 우리 데이터에 빠르게 적응한다.
Freezing vs Fine-tuning
- Freezing: 앞쪽 층을 모두 얼리고(가중치 업데이트 X), 새로 붙인 분류기만 학습. 데이터가 적을 때 안전.
- Fine-tuning: 사전 학습된 가중치를 출발점으로 두되 전체 (또는 일부) 층을 함께 학습. 데이터가 충분할 때 더 큰 성능 향상.
학습 로그
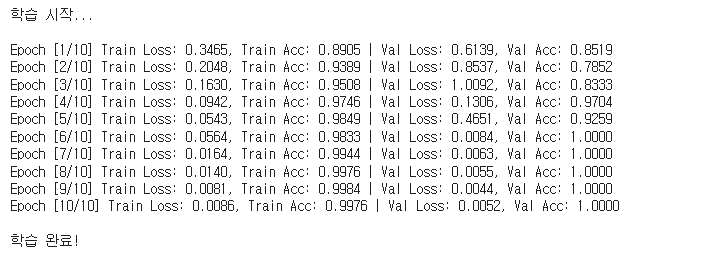
10 epoch 만에 Val Acc가 1.0에 도달했다. 이 단계에서는 “잘 됐다”가 아니라 “정말 잘 된 게 맞나(과적합 아닌가)?” 를 의심해야 한다. 곡선을 그려서 확인했다.
6. 학습 곡선 — 머신러닝 엔지니어의 기본기
학습 곡선을 읽을 줄 알아야 머신러닝 엔지니어다.
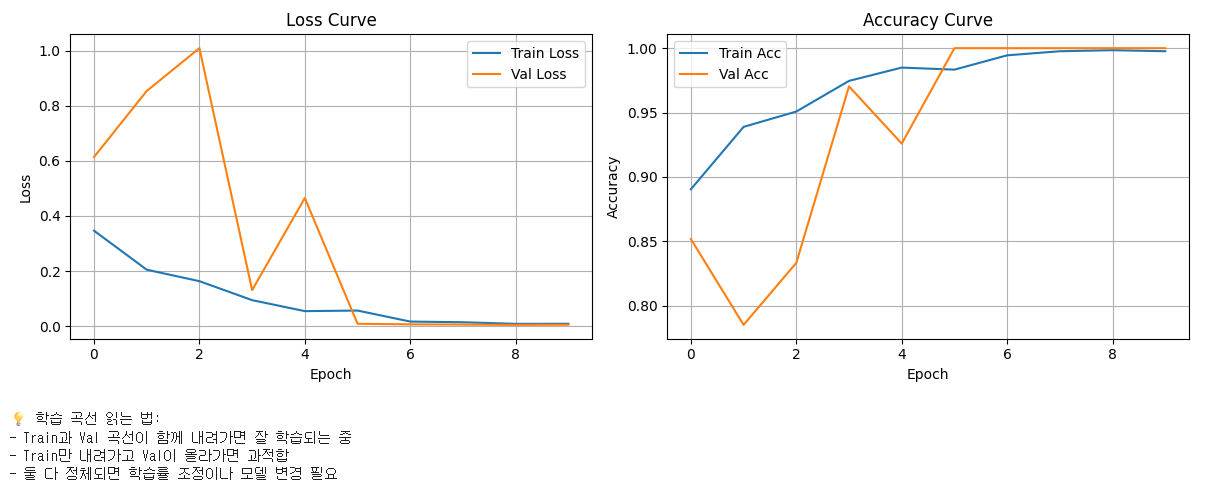
읽는 방법은 사실 직관적이다.
- Train과 Val이 함께 내려가면: 학습 잘 되고 있는 중
- Train만 내려가고 Val은 올라가면: 과적합. 모델이 학습 데이터를 외우기 시작함
- 둘 다 정체되면: 학습률 조정이나 모델 변경 필요
이번 곡선은 둘 다 수렴해서 정상적인 학습 양상이었다. 학습률(learning rate)에 대한 직관도 다시 짚어봤다: 너무 작으면 최저점 찾는 데 오래 걸리고, 너무 크면 최저점 근처에서 발산하기 쉽다.
7. Confusion Matrix — NDT에서 단순 정확도보다 중요한 것
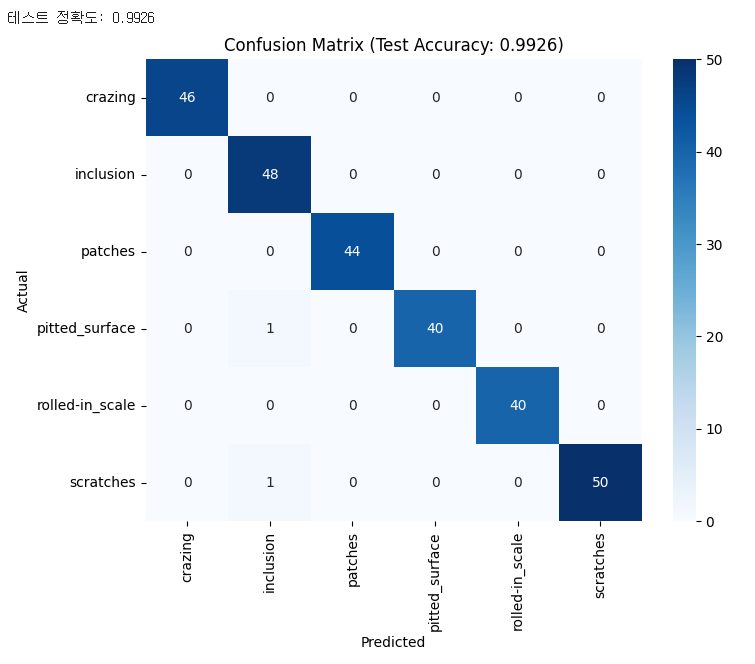
테스트 정확도 0.9926. 다만 NDT에서는 단순 정확도보다 어떤 클래스를 어떤 클래스로 헷갈리는지 가 훨씬 중요하다. Confusion Matrix가 그래서 필수.
특히 False Negative(결함을 놓치는 것)는 인명사고로 직결될 수 있어 가장 위험하다. False Positive(없는 결함을 있다고 하는 것)는 추가 검사 비용이 들지만 안전 측면에서는 덜 치명적이다.
그런데 — 왜 이 행렬에는 “결함 없음” 클래스가 없지?
Confusion Matrix를 보면서 처음에 헷갈렸다. 결함을 정상으로 분류하는 케이스가 안 보였다. 찾아보니 이유가 있었다.
실무 NDT 시스템은 보통 2단계 파이프라인이다.
- 결함 유무 판단 (binary)
- 결함 종류 분류 (multi-class)
내가 다룬 NEU 데이터셋은 2단계용 데이터셋이다. 즉 이미 결함이 있다는 전제 하에 6종 중 어느 것인지 가르는 모델. 그래서 “정상” 클래스 자체가 없고 False Negative 케이스도 행렬에 등장하지 않는다.
이 구조를 알고 나니 정확도 99.26%가 의미하는 게 좁아진다. “결함이 있다는 전제 하에 종류를 거의 완벽하게 가른다” 일 뿐, 1단계(유무 판단)의 신뢰도와는 별개의 이야기.
8. Grad-CAM — 모델이 어디를 보고 판단했는가
NDT 시스템이 실무에 도입되려면 단순한 분류 결과만으로는 부족하다. 검사자와 규제기관은 “왜 이 모델이 이렇게 판단했는지” 를 보고 싶어한다. 이를 위한 표준 도구가 Grad-CAM.
Grad-CAM은 모델이 분류 결정을 내릴 때 이미지의 어느 부분을 주로 봤는지 히트맵으로 시각화하는 기법.
(유사 기법으로 SHAP 등도 있다 — 모델 해석성 분야에는 여러 갈래의 도구가 있다.)
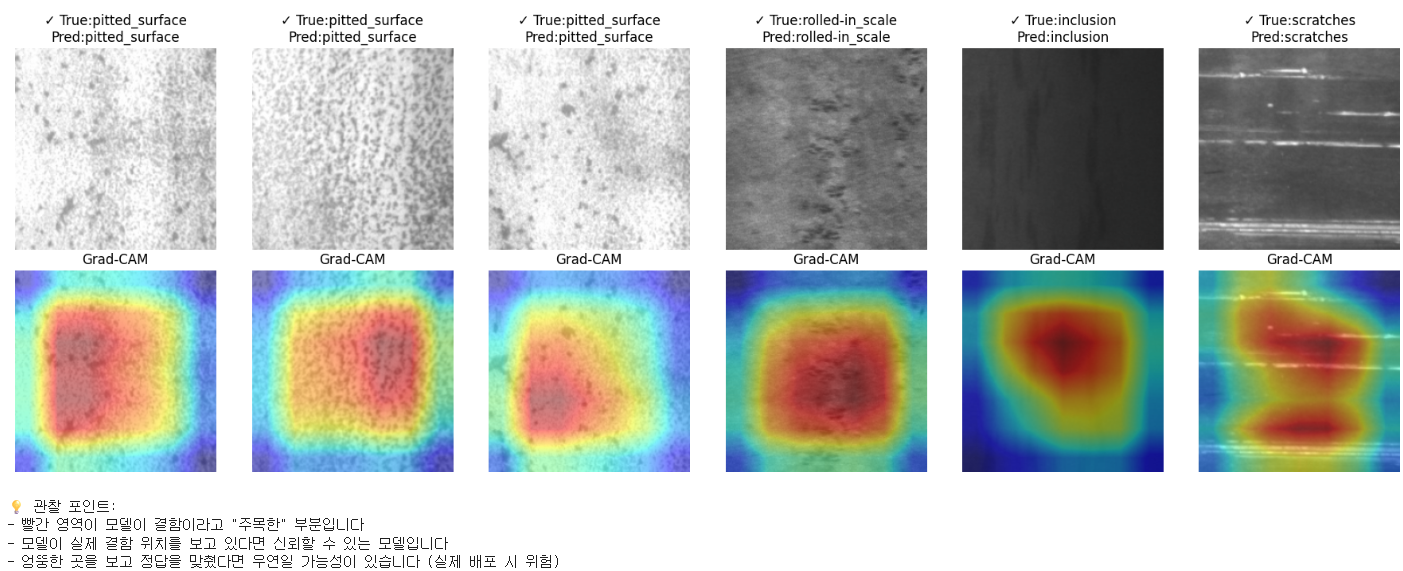
히트맵을 보면 모델이 결함 영역에 정확히 집중하고 있다. 만약 모델이 이미지 가장자리나 배경에 활성화되어 있었다면 “우연히 맞춘 것” 일 가능성이 컸을 것. Grad-CAM은 그걸 잡아주는 검증 도구다.
9. 모델 저장 및 추론 성능
마지막으로 모델을 저장하고, 임베디드 배포 가능성을 가늠하기 위해 파일 크기와 추론 속도를 측정했다.

- 파일 크기: 42.72 MB
- GPU 추론 속도: 평균 2.95ms / 이미지 (339.3 FPS)
- 1,000장 처리 시간: 약 2.9초
GPU 기준이라 매우 빠르지만, 실제 임베디드 환경(엣지 디바이스 / CPU 추론)에 올리려면 양자화(quantization) 같은 추가 최적화가 필수다. 이번엔 양자화 단계까지는 들어가지 않았다.
정리
- 전이학습 + 데이터 증강으로 적은 데이터에서도 99%대 분류 정확도 가능.
- NDT는 단순 정확도가 아니라 Confusion Matrix의 패턴, 특히 FN 양상 이 핵심.
- 실무 NDT는 2단계(유무 판단 + 종류 분류) 파이프라인 — 데이터셋의 성격을 알아야 결과를 옳게 해석한다.
- Grad-CAM은 모델 채택의 필수 도구 — 검사자/규제기관에게 모델의 판단 근거를 보여줄 수 있어야 한다.
더 공부해볼 것
1. 모델 양자화 (Quantization)
- INT8 / FP16 양자화 시 정확도 손실 vs 속도·메모리 개선 트레이드오프
- PyTorch의
torch.quantization워크플로우 (PTQ vs QAT) - 양자화한 모델을 ONNX로 변환해서 엣지 디바이스(Jetson, Raspberry Pi 등)에 배포
- 참고: PyTorch Quantization 공식 가이드
2. NDT 2단계 파이프라인 직접 구축
- 이번 모델(분류기) 앞에 결함 유무 판단 binary 모델을 붙여서 end-to-end 파이프라인 만들기
- 1단계의 False Negative를 줄이는 데 집중하는 학습 전략 (class weighting, focal loss 등)
- 1단계 + 2단계 결합 시 전체 시스템의 FN 율을 어떻게 측정·관리하는가
3. 모델 해석성 — Grad-CAM 너머
- Grad-CAM, Guided Grad-CAM, Score-CAM 의 차이
- SHAP / LIME 같은 모델 무관(model-agnostic) 해석 도구
- 의료·산업 도메인에서 모델 해석성이 규제 통과에 미치는 영향
- 참고: Grad-CAM 논문
4. PyTorch 핵심 개념 다시 짚기
이번 실습에서 익숙하지만 자세히 설명하기 어려웠던 개념들을 복습 거리로 정리.
nn.Linear의 내부 동작과 가중치 초기화- 손실 함수 종류 (CrossEntropy, BCE, Focal Loss) — 언제 어떤 것을 쓰나
- 옵티마이저 (SGD, Adam, AdamW) 의 차이와 선택 기준
- 학습률 스케줄링 (StepLR, CosineAnnealing 등)
- 참고: PyTorch 공식 튜토리얼
5. NDT 도메인 — 비전 기반 검사의 실무 흐름
- 데이터 수집 단계의 어려움 (희소 결함, 라벨 일관성, 환경 변동)
- 강철 외 도메인 (반도체 웨이퍼, 의료 영상, 항공 부품 등) 으로의 확장 시 공통점/차이점
- 산업 현장의 카메라/조명 셋업이 모델 성능에 미치는 영향
6. TensorFlow → PyTorch 전환
- 두 프레임워크의 핵심 차이점 (Static graph vs Dynamic graph, eager 실행, ecosystem)
- TF에서 짠 모델을 PyTorch로 옮길 때 자주 막히는 부분
- ONNX를 통한 양방향 변환
회고
이번 실습으로 두 가지가 명확해졌다.
첫째, 같은 분류 문제여도 도메인에 따라 평가 지표의 의미가 완전히 달라진다. “정확도 99%” 는 ImageNet 분류에서는 멋진 숫자지만, NDT에서는 “그래서 FN은 몇 개?” 를 다시 물어야 하는 시작점일 뿐이다.
둘째, 모델 해석성은 더 이상 옵션이 아니다. Grad-CAM 같은 도구로 모델의 판단 근거를 보여줄 수 없으면 산업 도메인 도입은 어렵다는 걸 직접 체감했다.
다음 단계는 위 “공부할 것” 의 1, 2번 — 양자화로 임베디드 배포 가능성을 확인하고, 2단계 NDT 파이프라인을 직접 구축해보는 것. 임베디드 객체 인식 경력과 이번 NDT 실습을 연결할 자리가 거기 있다.